🔦 llama.c source code analysis

随着大语言模型的流行,面向边缘设备部署的大语言模型部署工具如雨后春笋一般涌现。笔者分析了开源社区比较流行的几个大语言模型部署工具的源码,梳理一下比较流行的部署方案。本文分析的是llama.c.
前言
之所以选择llama2.c分析🧐,还是因为它只有一个不到1000行的c文件。这样梳理大模型的执行流程会简单很多。并且只有一个C文件,放进各种成熟的IDE里面都很简单,分析源码,借助IDE的函数跳转、调试这些功能更能理解的透彻一些。
源码
在run.c的main函数里面,有这么一段:
1 | // run! |
这里通过判断命令行传递的参数,选择执行生成模式和对话模型,在这里我们主要查看对话模式,对话模式根据常用
对话模式的入口chat函数的定义如下:
1 | void chat(Transformer *transformer, Tokenizer *tokenizer, Sampler *sampler, |
每个参数含义如下:
transformer: 这个参数用来加载模型的权重,运行时配置的超参,保存模型运行的状态,其中Transformer这个结构体定义如下:
1
2
3
4
5
6
7
8
9typedef struct {
Config config; // the hyperparameters of the architecture (the blueprint)
TransformerWeights weights; // the weights of the model
RunState state; // buffers for the "wave" of activations in the forward pass
// some more state needed to properly clean up the memory mapping (sigh)
int fd; // file descriptor for memory mapping
float* data; // memory mapped data pointer
ssize_t file_size; // size of the checkpoint file in bytes
} Transformer;tokenizer: 这个参数保存的是词对应的token,还有token的最大长度,其类型定义如下:
1
2
3
4
5
6
7
8typedef struct {
char** vocab;
float* vocab_scores;
TokenIndex *sorted_vocab;
int vocab_size;
unsigned int max_token_length;
unsigned char byte_pieces[512]; // stores all single-byte strings
} Tokenizer;sampler: 字如其名,一个采样器,作用就是对于输出的概率中选择概率较大的词作为下一个提示词,其定义如下:
1
2
3
4
5
6
7typedef struct {
int vocab_size;
ProbIndex* probindex; // buffer used in top-p sampling
float temperature;
float topp;
unsigned long long rng_state;
} Sampler;cli_user_prompt: 就是命令行,输入的提示词
cli_system_prompt: 命令行中,系统提示词
steps: 限制生成的提示词的数量
主要的执行流程在这个函数的while循环里面,在这个while的每一轮循环里面,首先会判断是不是轮到用户提问,这里通过user_turn的值来判断,在用户提问阶段,程序先判断命令行参数是否为空,如果为空,就从标准输入读取用户输入,不空就直接使用。对于用户的提示词使用encode函数得到对于的词向量表示。
1 | int8_t user_turn = 1; // user starts |
对于每一个token,无论用户输入还是模型生成,程序都会通过forward函数调用模型输出下一个词的概率,
让用sample和采样器得到可能性最大的词的词向量,如果当前词在句子中的位置没有超过是用户输入的词的长度,程序没有使用预测得到的结果。对于模型生成的词,会调用decode函数得到可读的词表示,然后在标准输出中显示。
大模型结构
大模型外部运行流程比较简单,就是对于每一个词,通过模型预测下一个词,通过预测的下一个词再预测下一个词,如此循环往复,直到遇到EOS(序列结束符)或者到了最大的句子长度,才停止。那么在大模型里面是怎么保存上下文信息的呢?
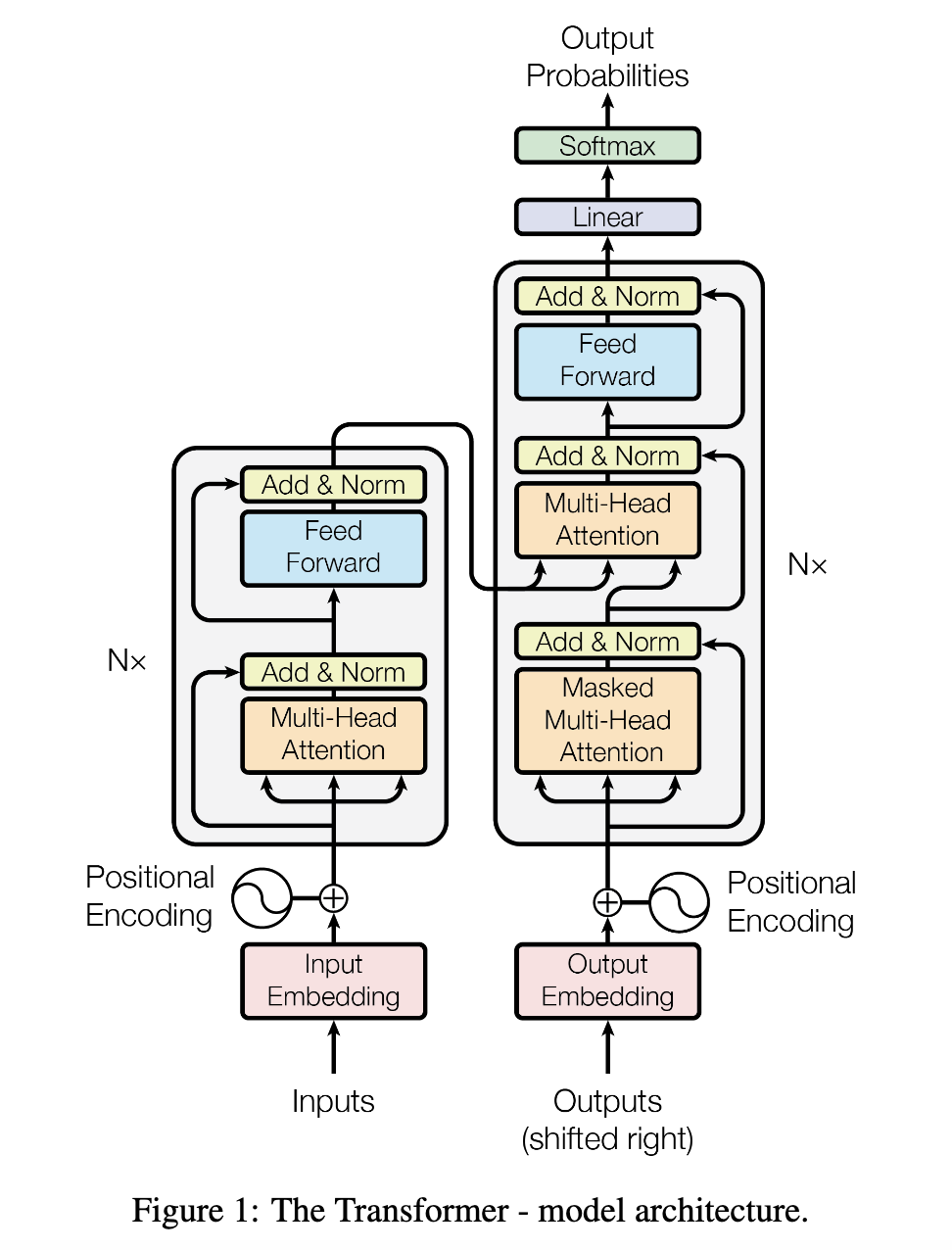
现在主流的大语言模型的主要是由Transformer块堆叠而成,在Transformer架构里面,包含了编码器和解码器,主流的大模型都只
使用了解码器这一部份
问题
在chat模式中,用户输入的每个词,运行模型的到预测的下一个词,这个模型预测的词没有使用。另外在llama.cpp中,对于用户输入的词,有使用批处理和多线程处理。这里考虑移动端的内存限制,并行越高的
情况下,程序占用的峰值内存会变大。也许单线程这种简单的方式可以避免不少问题吧
- 本文链接: https://blog.saltpi.cn/article/source-llama-c/
- 版权声明: 本博客所有文章除特别声明外,均采用 ©BY-NC-SA 许可协议。转载请注明出处!