虚拟机集群配置

虚拟系统选择
磁盘空间有限,因为至少需要3个虚拟机实例,这里选择的是Alpine系统作为服务器系统,磁盘映像文件大小不到200MB。启动速度也很快。
配置集群
主要是5个配置文件,配置一个后,使用rsync分发到其他机器,bash支持循环语句:
1 | for host in vm02 vm03; do echo $host; done |
5个配置文件分别是:
etc/hadoop/core-site.xmletc/hadoop/hdfs-site.xmletc/hadoop/yarn-site.xmletc/hadoop/mapred-site.xmletc/hadoop/workers
由于模块化的设计,hdfs负责分布式文件存储,yarn负责资源调度,mapreduce负责计算
分布式文件系统的设计借鉴了FAT文件系统、RAID磁盘阵列的处理方式。
HDFS有一个NameNode, 一个SecondaryNameNode, 和若干个DataNode, NameNode负责存储元数据信息(文件名称、副本数等等), 类似FAT文件系统的间接索引, DataNode存储的是真实的数据, 类似于直接索引。
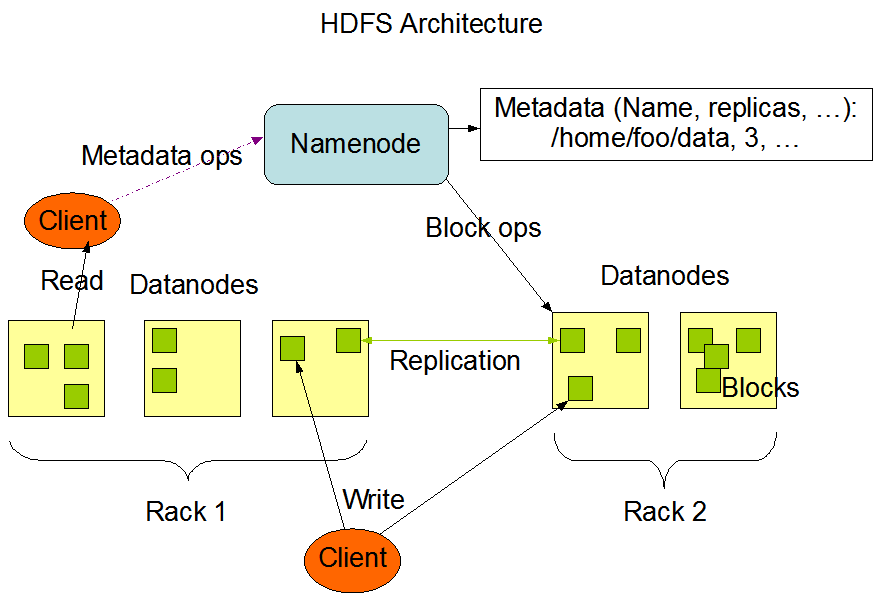
配置文件参考
各个机器的具体配置
| 机器 | 功能 |
|---|---|
| vm01 | NameNode DataNode NodeManager |
| vm02 | ResourceManager DataNode NodeManager |
| vm03 | SecondaryNameNode DataNode NodeManager |
core-site.xml
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://vm01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/lib/hadoop-3.3.1/data</value>
</property>
</configuration>hdfs-site.xml
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>dfs.namenode.http-address</name>
<value>vm01:9870</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>vm03:50090</value>
</property>
</configuration>yarn-site.xml
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>vm02</value>
</property>
</configuration>mapred-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/lib/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/lib/hadoop-3.3.1</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/usr/local/lib/hadoop-3.3.1</value>
</property>
</configuration>
遇到的问题
无法设置进程优先级
这个查看logs下面的out日志后发现是JAVA共享库的路径没有设置, 在环境变量的脚本里面设置LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/amd64/server即可无法启动yarn
查看日志后发现找不到bash, alpine默认的shell是ash, 即使你安装了bash, 它找不到, 这里的解决方法是修改用户登录的shell, 我修改/etc/passwd下面当前用户的shell为bash就正常了.还是找不到
bash
移除gcompat, 换glibc1
2
3
4
5
6export GLIBC_VERSION="2.34-r0"
sudo wget -q -O /etc/apk/keys/sgerrand.rsa.pub https://alpine-pkgs.sgerrand.com/sgerrand.rsa.pub
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/$GLIBC_VERSION/glibc-$GLIBC_VERSION.apk -O /tmp/glibc-$GLIBC_VERSION.apk
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/$GLIBC_VERSION/glibc-bin-$GLIBC_VERSION.apk -O /tmp/glibc-bin-$GLIBC_VERSION.apk
wget https://github.com/sgerrand/alpine-pkg-glibc/releases/download/$GLIBC_VERSION/glibc-i18n-$GLIBC_VERSION.apk -O /tmp/glibc-i18n-$GLIBC_VERSION.apk
sudo apk add /tmp/glibc-$GLIBC_VERSION.apk /tmp/glibc-bin-$GLIBC_VERSION.apk /tmp/glibc-i18n-$GLIBC_VERSION.apkfind不支持ls选项
alpine的find命令不是gnu版本的, 需要额外安装sudo apk add findutils集群之间的服务无法访问
用netstat -anp查看了端口和监听的IP, 发现IP都是127.0.0.1, 这个地址是环路地址, 流量不经过网卡适配器, 如果需要将外部访问的流量全部定向到127.0.0.1需要打开内核的一个路由配置:1
2sudo sysctl -w net.ipv4.conf.eth0.route_localnet=1
sudo sysctl -w net.ipv4.ip_forward=1
然后防火墙配置重定向
1 | sudo iptables -F -t nat |
- 遇到这个多问题, 接下来可能还有问题, map-reduce任务失败,我建议你不要用alpine了,换fedora, fedora不会遇到这么多问题, 这就和葵花宝典最后一页, 不必自宫, 也能成功 :D!
- 本文链接: https://blog.saltpi.cn/article/hadoop-cluster/
- 版权声明: 本博客所有文章除特别声明外,均采用 ©BY-NC-SA 许可协议。转载请注明出处!