链接

graph LR editor>编辑] editor-. hello.c
源程序文本 .-cpp["预处理器
(cpp)"] cpp-. hello.i
修改了的源程序文本 .-> cc1["编译器
cc1"] cc1-. hello.s
汇编程序文本 .->as["汇编器
(as)"] as-. hello.o
可重定位目标文件二进制 .->ld["链接器
(ld)"] ld-. hello
可执行目标程序二进制 .-> done["结束"] printf{printf.o}-->ld style ld fill:#ccf,stroke:#f66,stroke-width:2px,stroke-dasharray: 5, 5
安装工具
我的机器环境是:macOS Mojave 10.14.4 18E226 x86_64,开始之前,得在机器上面安装一些工具:
- gcc
- binutils (readelf,objdump)
因为我在自己的机器上面安装了 brew这个包管理工具,以及zsh这个 Shell,所以我就通过brew install gcc binutils就安装好了gcc、objdump和readelf这3个命令,值得注意的是,由于macOS上面也提供了和binutils相同功能的工具,我们就需要手动将这两个命令的路径添加到环境变量里面:
1 | echo 'export PATH="/usr/local/opt/binutils/bin:$PATH"' >> ~/.zshrc #使用bash的话,就添加到.bashrc里面 |
如果需要让编译器找到这些命令,还需要额外添加:
1 | export LDFLAGS="-L/usr/local/opt/binutils/lib" |
书上📚说,Window使用可移植可执行(Portable Executable,PE)格式,MacOS-X使用Mach-O格式,现代x86-64 Linux和Unix系统使用可执行可链接格式(Executable and Linkable Format,ELF)。也就是说macOS并没有继承Unix使用elf作为可执行文件的格式,我用gcc编译了一下,在用readelf查看编译生成的可执行文件,显示结果为:
readelf:错误:不是 ELF 文件 - 它开头的 magic 字节错误
所以我得在linux下面编译文件,以前学jsp的使用写了个fedora的镜像构建脚本,打开了ssh,这样编译好的文件就可以通过scp来传输到宿主机器。不过为了方便我还是挂载了一个目录到fedora。
1 | docker pull ourfor/tomcat |
创建一个名为asm的容器,同时将当前目录挂载到/root目录
fedora上面的包管理工具有yum和dnf,为了方便,我还是安装下gcc和binutils以及vim
1 | dnf install gcc binutils vim -y |
在fedora里面编译好,再打开一个Terminal,到挂载的共享目录就可以查看编译好的文件
这个结果和fedora里面用readelf看到的结果是一样的:
1 | ELF Header: |
要用到的工具我们都安装完了。
测试代码
解压后,发现目录里面存在.o文件和Makefile.txt,打开看了一下,貌似没有什么问题,就重命名为Makefile,估计是为了查看里面的内容才添加了.txt的拓展名。执行make clean清理多余的文件。执行make命令,由于:
1 | gcc -Wall -Og -static -o prog2c main2.o -L. -lvector |
使用的是静态链接,所以我们得安装静态链接库,这样在链接的时候才不会报错:
1 | dnf install glibc-static -y |
在Makefile里面,反编译的结果都被重定向保存在以.d为拓展名的文件里面
在ppt里面有这样一部分代码:
symbols.c
1 |
|
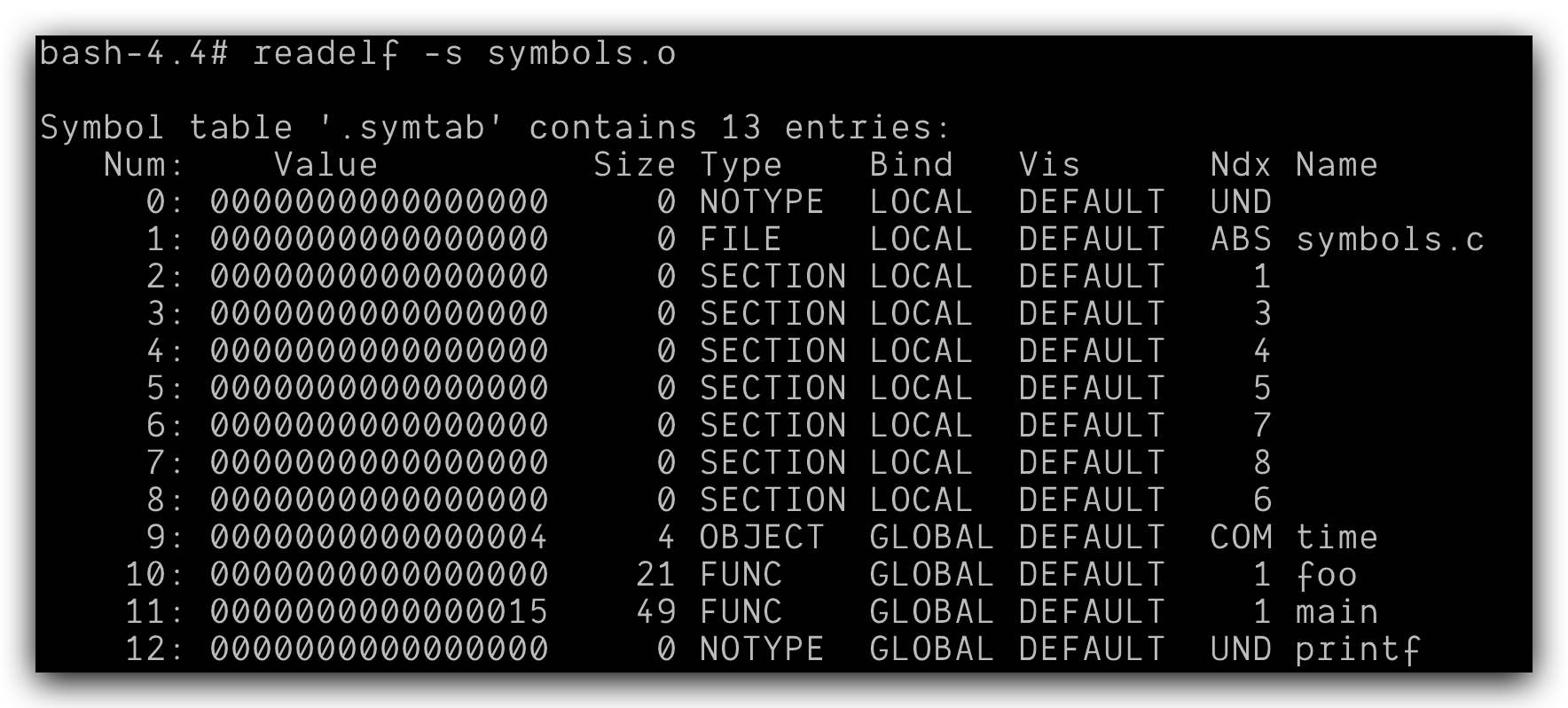
在这个里面存储在.data这一节的符号有foo main,这两个是全局函数,存储在.bss这一节的有time因为它被定义没有被初始化。同时printf这个符号显示未定义,是因为还没有链接。
| 符号 | .symtab条目? | 符号类型 | 在哪个模块定义 | 节 |
|---|---|---|---|---|
| foo | 是 | 全局 | symbols.c | .data |
| main | 是 | 全局 | symbols.c | .data |
| time | 是 | 全局 | symbols.c | COMMON |
| printf | 是 | 外部 | 其他模块 | UNDEF |
| b | 否 | - | - | - |
(三个伪节:1.ABS表示不该被重定位的符号 2.UNDEF表示未定义的符号,也就是在本模块被引用,在其他模块被定义的 3.COMMON表示还未被被分配位置的未初始化的的数据条目)
使用gcc -c symbols.c得到一个可重定位的文件symbols.o,使用readelf -s symbols.o来查看这个可重定位文件的符号表:
结果和我们分析的一致
使用objdump -dx -j .text symbolx.o来看看函数的汇编代码:
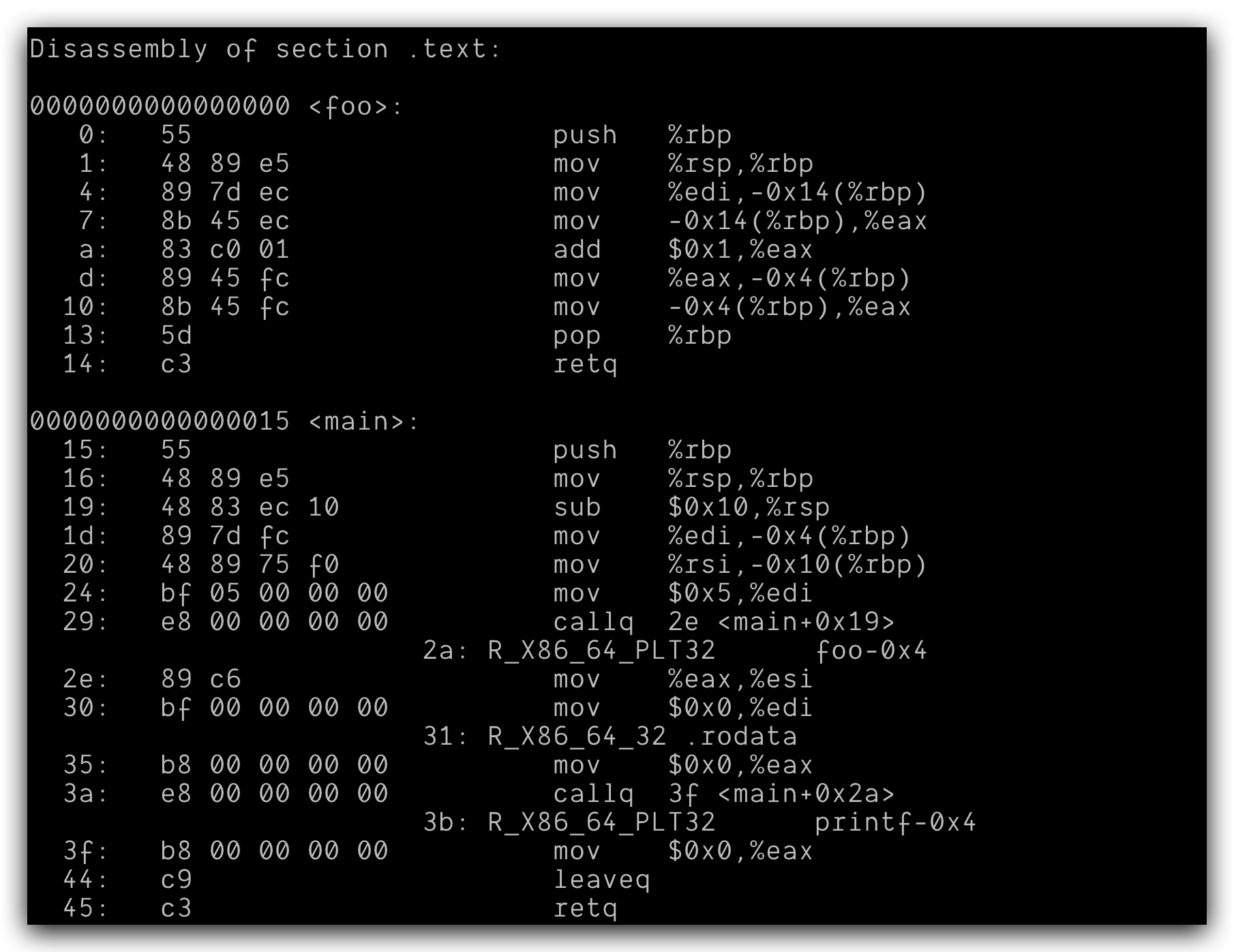
从上面👆的汇编里面main函数部分,首先压栈,栈指针减去16个字节,原先的栈指针地址保存在基指针(%rbp)中,然后将argc和argv保存到了栈里面,接下来调用foo(5),接下来将foo(5)的返回值保存在寄存器%esi里面作为printf函数的第二个参数,这里面显示.rodata,应该是保存了printf的格式字符串,可以链接以后使用objdump -dx -j .rodata symbols查看:
402010: 25 64 0a 00 %d..
链接
链接(linking)是将各种代码和数据片段收集并组合编译成一个单一文件的过程,这个文件📃可被加载(复制)到内存并执行。
比如我们在Shell下面输入下面的命令来编译main.c和sum.c这两个文件
1 | gcc -Og -o prog main.c sum.c |
它实际上经过了下面👇几个过程:
graph TB main.c-->B["翻译器
(cpp,ccl,as)"] B-. main.o .-> E sum.c --> D["翻译器
(cpp,ccl,as)"] D-. sum.o .-> E["链接器
(ld)"] E --链接--> F[prog
完全链接的可执行目标文件]
sum.c源码:
1 | int sum(int *a,int n){ |
main.c源码:
1 | int sum(int *a,int n); |
接下来使用gcc编译这两个文件为可重定位文件:
1 | gcc -c main.c sum.c |
得到main.o和sum.o这两个可重定位文件,使用 -S 可以得到汇编文件(-masm=intel可以得到intel格式汇编,见118页),比如下面的main.c得到的汇编代码:
1 | __TEXT,__text,regular,pure_instructions |
目标文件
目标文件有三种格式:
- 可重定位目标文件。 包含二进制数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行的目标文件
- 可执行目标文件。包含二进制数据,其形式可以被直接复制到内存并执行
- 共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态的加载进内存并链接
以前在编译httpd的时候就了解了这三种文件,比如Apache的模块就是共享目标文件,Apache连接tomcat的mod_jk.so就是这种类型的,可执行文件就是编译好可以直接运行的文件,在使用make命令编译的时候,如果遇到库丢失,安装好依赖后,不会再重新编译,而是在编译好的.o文件的基础上面继续编译其它没有编译的源文件。
可重定位目标文件
一个典型的ELF可重定位目标文件的格式如下表所示。ELF头以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。
| 节 | ELF头 |
| .text | |
| .rodata | |
| .data | |
| .bss | |
| .symtab | |
| .rel.text | |
| .rel.data | |
| .debug | |
| .line | |
| .strtab | |
| 描述目标文件的节 | 节头部表 |
在Computer Systems A Programmer’s Perspective Third Edition这本书的练习题7.1里面有这样两个源文件:
m.c
1 | void swap(); |
swap.c
1 | extern int buf[]; |
使用命令:gcc -c m.c swap.c得到两个可重定位的目标文件,分别是m.o和swap.o,接下来用readelf来查看m.o的符号表:
1 | Symbol table '.symtab' contains 11 entries: |
因为swap和main是全局函数,由于m.c调用了swap.c里面定义的函数,还没有将这两个文件编译成一个可执行文件,所以在这里swap显示UND(表示未定义的符号),保存在.data这一节里面,buf是在 m.c里面初始化的全局变量,也是保存在.data里面.
同样的我们来查看下swap.o里面的信息:
1 | Symbol table '.symtab' contains 12 entries: |
在这里,我们可以看到bufp1的Ndx显示为COM(表示未初始化的全局变量),buf是在m.c里面定义的全局变量,在swap.c里面声明时用关键字extern指出这是一个外部符号,所以它Ndx这一项显示UND。
将这两个重定位文件编译成一个可执行的目标文件gcc -o prog m.o swap.o,在使用readelf查看prog的符号表:
1 | .... |
可以看到这里面buf和swap都可以正确显示.
接下来我们来看看m.o的ELF头信息,使用命令:readelf -h m.o:
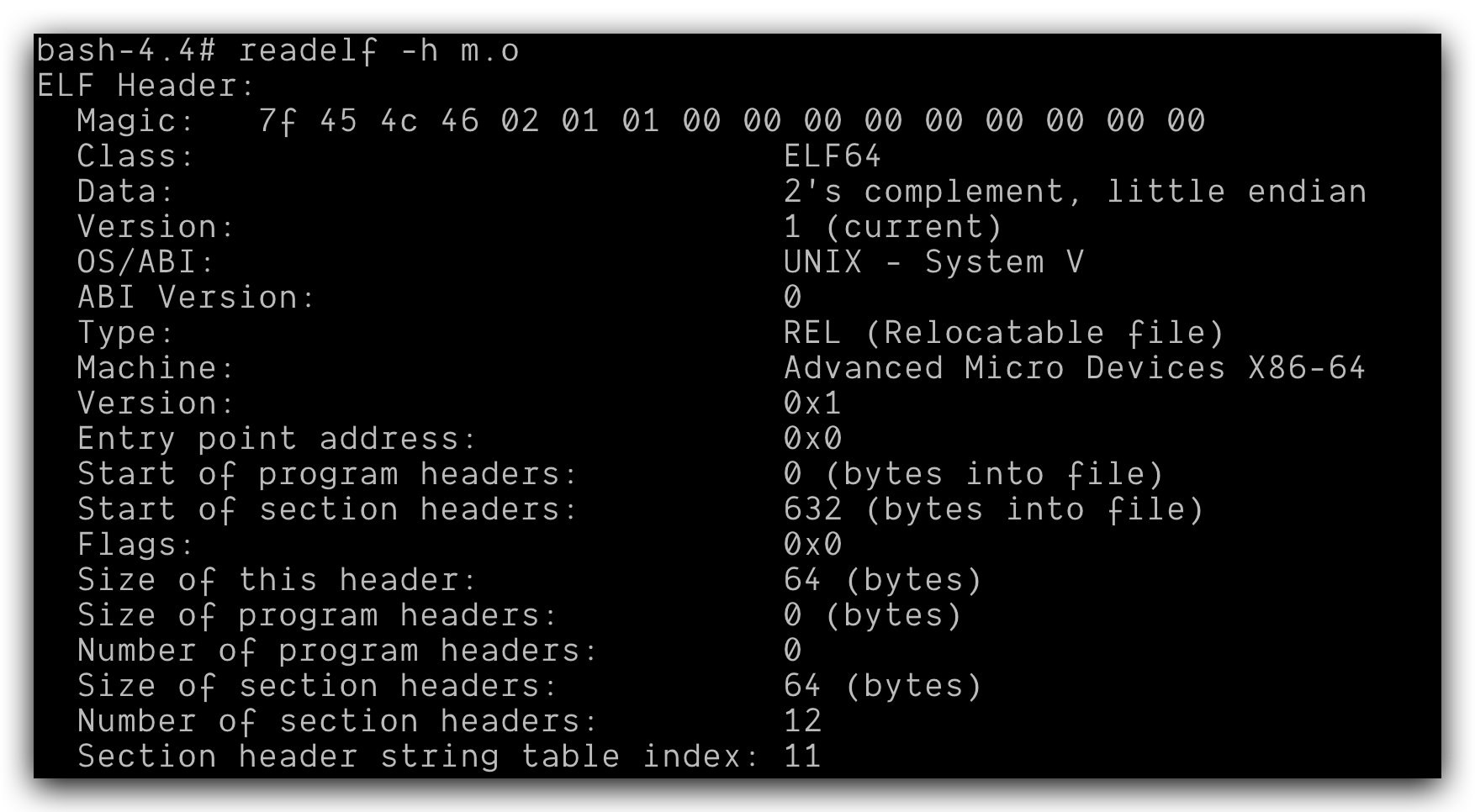
上面👆的Data表示:采用二进制补码和小端法,头的节大小为64个字节,头里面一共12节。文件类型在Type字段给出,属于可重定位文件
再用readelf -S m.o查看一下文件头的节: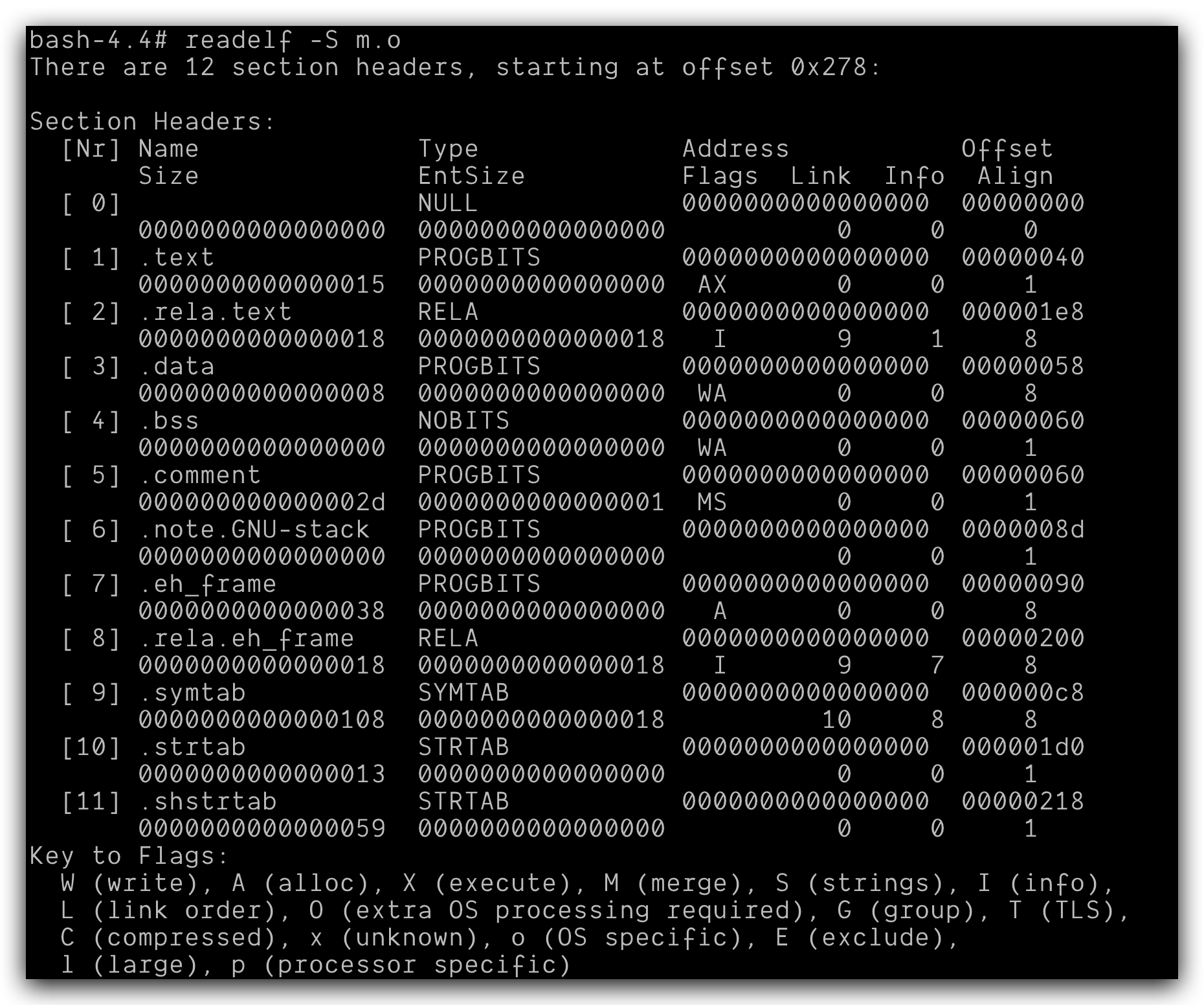
一共12节,和刚才头里面显示的信息是一致的
关于readelf:
Usage: readelf elf-file(s)
Display information about the contents of ELF format files
Options are:
-a --all Equivalent to: -h -l -S -s -r -d -V -A -I
-h --file-header Display the ELF file header
-l --program-headers Display the program headers
--segments An alias for --program-headers
-S --section-headers Display the sections' header
--sections An alias for --section-headers
-g --section-groups Display the section groups
-t --section-details Display the section details
-e --headers Equivalent to: -h -l -S
-s --syms Display the symbol table
--symbols An alias for --syms
--dyn-syms Display the dynamic symbol table
是一个用于显示ELF格式文件信息的工具,上面只列出了一些基本的用法。-h用于查看文件头,-S用于查看ELF节的信息,-s用于查看符号表。
符号解析
- 不允许有多个同名的强符号.
- 如果有一个强符号和多个弱符号同名,那么选择弱符号.
- 如果有多个弱符号同名,那么从这些弱符号中任意选择一个.
/good.jpg)
首先的弄清强符号和弱符号的概念, 强符号 是指定义的全局函数和初始化的全局变量,而 弱符号 则是指没有初始化的全局变量和局部变量
接下来我们通过几个例子来看看实际的效果,考虑下面👇两个程序源码:
a.c
1 | int x = 100; |
b.c
1 | int x = 20; |
使用gcc同时编译这两个文件,可以得到如下提示:
1 | /usr/bin/ld: /tmp/ccusXwhf.o:(.data+0x0): multiple definition of `x'; /tmp/ccBZMduP.o:(.data+0x0): first defined here |
并且是ld阶段出现的错误❌,这就是规则一
对于规则2,将b.c中x的定义修改为:int x;,在次进行编译,编译通过,查看生成的可执行文件的符号表,发现只有一个符号 x
对于规则3,考虑下面的例子:
a.c
1 | int x; |
b.c
1 | int x; |
链接这两个文件, 然后查看一下符号表,可以
mismatch-main.c
1 | long int x; |
mismatch-variable.c
1 | double x = 3.14; |
使用gcc -o mismatch mismatch-main.c mismatch-variable.c编译生成可执行文件,执行mismatch,得到结果4614253070214989087,得到这样的结果感觉一点也不意外,在mismatch-variable里面定义了强符号x类型为double,初始值为 3.14,在mismatch-main里面定义了弱符号x,类型为long int,因此printf语句中的占位符为%ld,由于强符号优先,所以x的值被解释为为long输出显示.
1 | 0 100 0000 0000 1 001 0001 1110 1011 1000 0101 0001 1110 1011 1000 0101 0001 1111 |
使用objdump反汇编
查看编译器优化后生成的汇编代码,进而改进C语言源码,从而使程序性能最大化。不过大多时候编译器比较保守,这就需要我们编写出容易优化的代码,来帮助编译器。
不过在这里,我们使用它来查看ELF节的信息,它有几个命令行参数比较重要:
-d: 反汇编,生成反汇编代码-x: 显示所有的头部的内容-j: 只显示指定的节,例如-j .data只显示.data这一节的信息
比如下面这个打印Hello World的程序:
main.c
1 |
|
使用gcc -o main main.c编译它。得到main,分别查看它的节的信息:
听说👂Hello World保存在.rodata里面,试一下:objdump -dx -j .rodata main,结果显示:
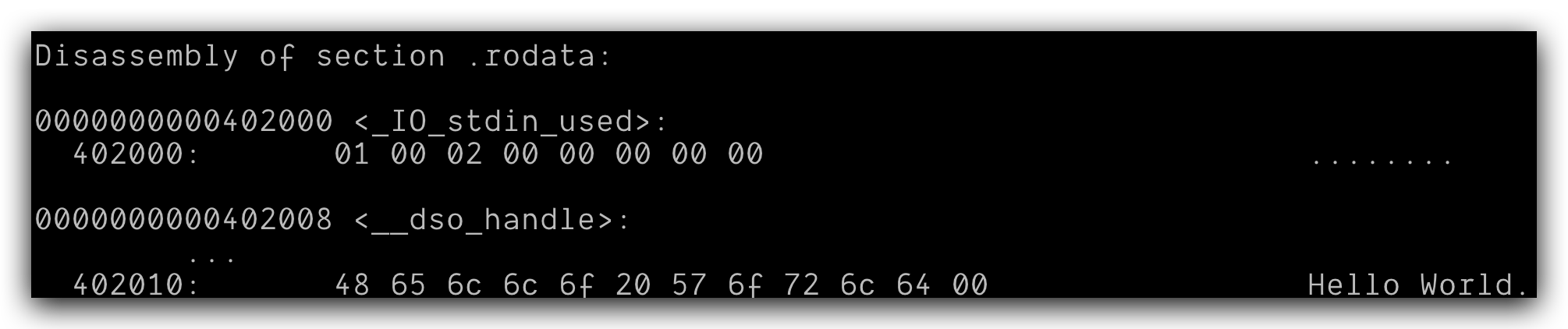
对于符号解释
符号可以分为3种符号
- 全局符号. 由模块m定义并能够被其他模块引用的符号。例如,非
staticC函数和非static的C全局变量(指不带static的全局变量) - 外部符号. 由其他模块定义并被模块m定义的符号,使用前需要进行原型说明
- 局部符号. 仅有模块m定义和引用的本地符号
链接器局部符号不是指程序中的局部变量(分配在栈中的临时性变量),链接器不关心这种局部变量
首先的弄清强符号和弱符号的概念, 强符号 是指定义的全局函数和初始化的全局变量,而 弱符号 则是指没有初始化的全局变量和局部变量
考虑下面👇两个程序:
a.c
1 | int x = 100; |
b.c
1 | int x = 20; |
使用gcc同时编译这两个文件,可以得到如下提示:
1 | /usr/bin/ld: /tmp/ccusXwhf.o:(.data+0x0): multiple definition of `x'; /tmp/ccBZMduP.o:(.data+0x0): first defined here |
并且是ld阶段出现的错误❌,这就是规则一
对于规则2,将b.c中x的定义修改为:int x;,在次进行编译,编译通过,查看生成的可执行文件的符号表,发现只有一个符号 x
对于规则3,考虑下面的例子:
a.c
1 | int x; |
b.c
1 | int x; |
静态链接
静态链接需要使用ar这个命令
下面有三个c语言源文件:
main.c
1 |
|
add.c
1 | int add(int a,int b){ |
add.h
1 | int add(int,int); |
执行下面的命令:
1 | gcc -o add.o -c add.c |
可以看到输出的结果为:3 + 4 = 7
- 本文链接: https://blog.saltpi.cn/article/compile-link/
- 版权声明: 本博客所有文章除特别声明外,均采用 ©BY-NC-SA 许可协议。转载请注明出处!